Este guia é para usuários atuais do ClickHouse Cloud. Se você está começando no ClickHouse Cloud, recomendamos nosso guia de Primeiros passos para o Managed ClickStack.
Nesse padrão de implantação, tanto o ClickHouse quanto a UI do ClickStack (HyperDX) são hospedados no ClickHouse Cloud, minimizando a quantidade de componentes que o usuário precisa hospedar por conta própria.
Além de reduzir o gerenciamento da infraestrutura, esse padrão de implantação garante que a authentication esteja integrada ao SSO/SAML do ClickHouse Cloud. Ao contrário das implantações self-hosted, também não é necessário provisionar uma instância do MongoDB para armazenar o estado da aplicação — como dashboards, pesquisas salvas, configurações do usuário e alertas. Os usuários também se beneficiam de:
- Escalonamento automático da capacidade computacional, independentemente do armazenamento
- Retenção de baixo custo e praticamente ilimitada com base em armazenamento de objetos
- A capacidade de isolar de forma independente workloads de leitura e gravação com Warehouses.
- Authentication integrada
- Backups automatizados
- Recursos de segurança e compliance
- Upgrades sem interrupções
Nesse modo, a ingestão de dados fica inteiramente a cargo do usuário. Você pode ingerir dados no Managed ClickStack usando seu próprio collector do OpenTelemetry hospedado, ingestão direta por bibliotecas cliente, motores de tabela nativos do ClickHouse (como Kafka ou S3), pipelines de ETL ou ClickPipes — o serviço gerenciado de ingestão do ClickHouse Cloud. Essa abordagem oferece a maneira mais simples e com melhor desempenho de operar o ClickStack.
Esse padrão de implantação é ideal nos seguintes cenários:
- Você já tem dados de observabilidade no ClickHouse Cloud e deseja visualizá-los com o ClickStack.
- Você opera uma implantação de observabilidade em grande escala e precisa do desempenho dedicado e da escalabilidade do ClickStack em execução no ClickHouse Cloud.
- Você já usa o ClickHouse Cloud para analytics e quer instrumentar sua aplicação usando as bibliotecas de instrumentação do ClickStack — enviando dados para o mesmo cluster. Nesse caso, recomendamos usar warehouses para isolar a capacidade computacional das cargas de trabalho de observabilidade.
O guia a seguir pressupõe que você já criou um serviço do ClickHouse Cloud. Se ainda não criou um serviço, siga o guia Primeiros passos para Managed ClickStack. Ao final, você terá um serviço no mesmo estado descrito neste guia, ou seja, pronto para dados de observabilidade com o ClickStack ativado.
Crie um novo serviço
Use um serviço existente
Crie um novo serviço
Na página inicial do ClickHouse Cloud, selecione New service para criar um novo serviço.Especifique seu provedor, a região e o recurso
Scale vs EnterpriseRecomendamos este nível Scale para a maioria das cargas de trabalho do ClickStack. Escolha o nível Enterprise se precisar de recursos avançados de segurança, como SAML, CMEK ou conformidade com HIPAA. Ele também oferece perfis de hardware personalizados para implantações muito grandes do ClickStack. Nesses casos, recomendamos entrar em contato com o suporte. 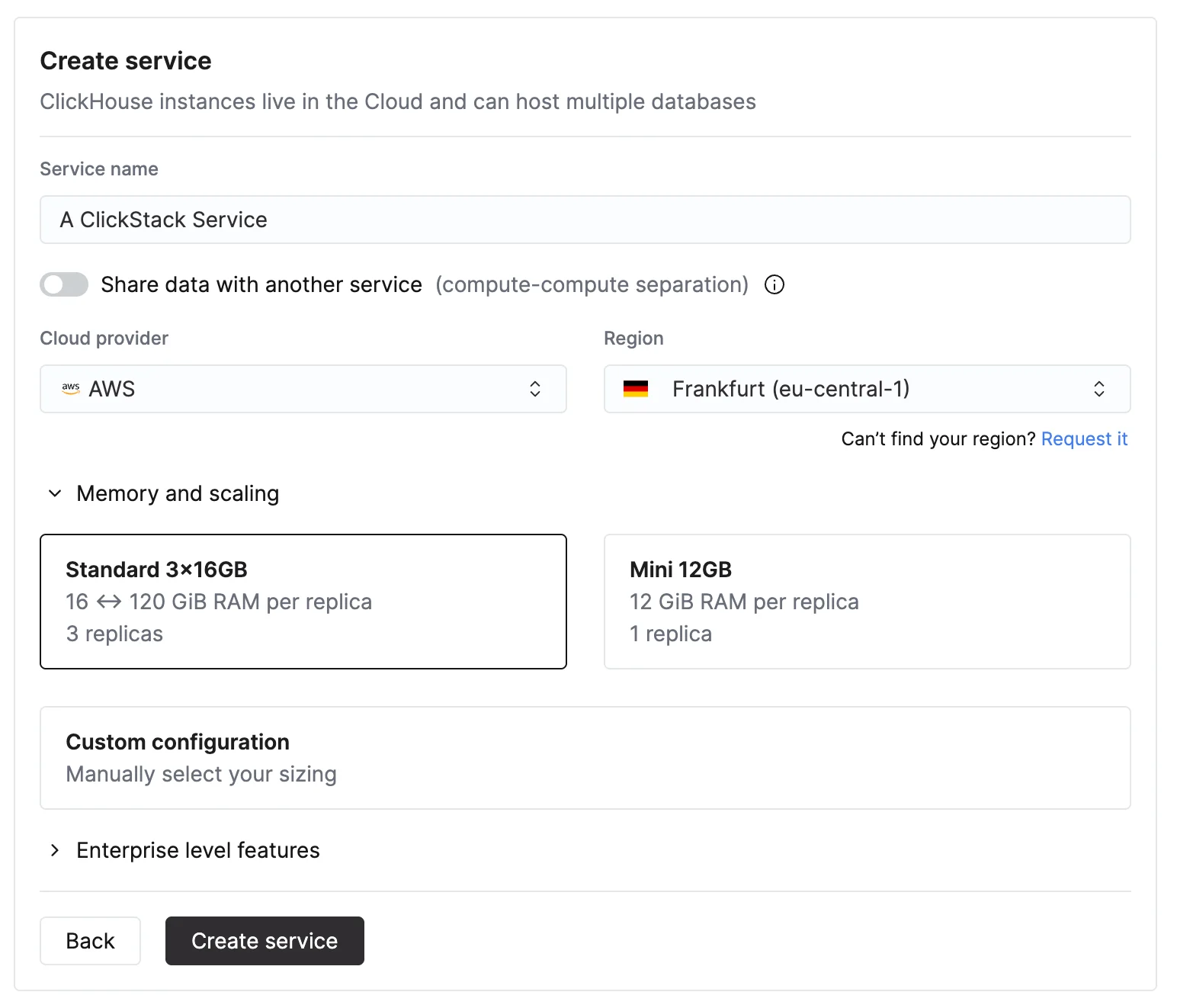 Ao definir a CPU e a memória, faça uma estimativa com base na taxa de ingestão esperada do ClickStack. A tabela abaixo fornece orientações para dimensionar esses recursos.
Ao definir a CPU e a memória, faça uma estimativa com base na taxa de ingestão esperada do ClickStack. A tabela abaixo fornece orientações para dimensionar esses recursos.| Volume mensal de ingestão | Capacidade computacional recomendada |
|---|
| < 10 TB / mês | 2 vCPU × 3 réplicas |
| 10–50 TB / mês | 4 vCPU × 3 réplicas |
| 50–100 TB / mês | 8 vCPU × 3 réplicas |
| 100–500 TB / mês | 30 vCPU × 3 réplicas |
| 1 PB+ / mês | 59 vCPU × 3 réplicas |
- O volume de dados se refere ao volume mensal de ingestão não compactado e se aplica tanto a logs quanto a traces.
- Os padrões de consulta são típicos de casos de uso de observabilidade, com a maioria das consultas direcionadas a dados recentes, normalmente das últimas 24 horas.
- A ingestão é relativamente uniforme ao longo do mês. Se você espera tráfego irregular ou picos, deve provisionar capacidade adicional.
- O armazenamento é tratado separadamente por meio do armazenamento de objetos do ClickHouse Cloud e não é um fator limitante para retenção. Presumimos que dados retidos por períodos mais longos sejam acessados com pouca frequência.
Pode ser necessária mais capacidade computacional para padrões de acesso que consultam regularmente intervalos de tempo mais longos, realizam agregações pesadas ou atendem a um grande número de usuários simultâneos.Embora duas réplicas possam atender aos requisitos de CPU e memória para uma determinada taxa de ingestão, recomendamos usar três réplicas sempre que possível para alcançar a mesma capacidade total e melhorar a redundância do serviço.Esses valores são apenas estimativas e devem ser usados como uma linha de base inicial. Os requisitos reais dependem da complexidade da consulta, da concorrência, das políticas de retenção e da variação na taxa de ingestão. Sempre monitore o uso de recursos e escale conforme necessário.
Depois que seu serviço for provisionado, verifique se ele está selecionado e clique em “ClickStack” no menu à esquerda. Selecione “Start Ingestion” e será solicitado que você escolha uma fonte de ingestão. O Managed ClickStack oferece suporte a OpenTelemetry e Vector como suas principais fontes de ingestão. No entanto, os usuários também podem enviar dados diretamente para o ClickHouse em um schema próprio usando qualquer uma das integrações compatíveis com o ClickHouse Cloud.
Selecione “Start Ingestion” e será solicitado que você escolha uma fonte de ingestão. O Managed ClickStack oferece suporte a OpenTelemetry e Vector como suas principais fontes de ingestão. No entanto, os usuários também podem enviar dados diretamente para o ClickHouse em um schema próprio usando qualquer uma das integrações compatíveis com o ClickHouse Cloud.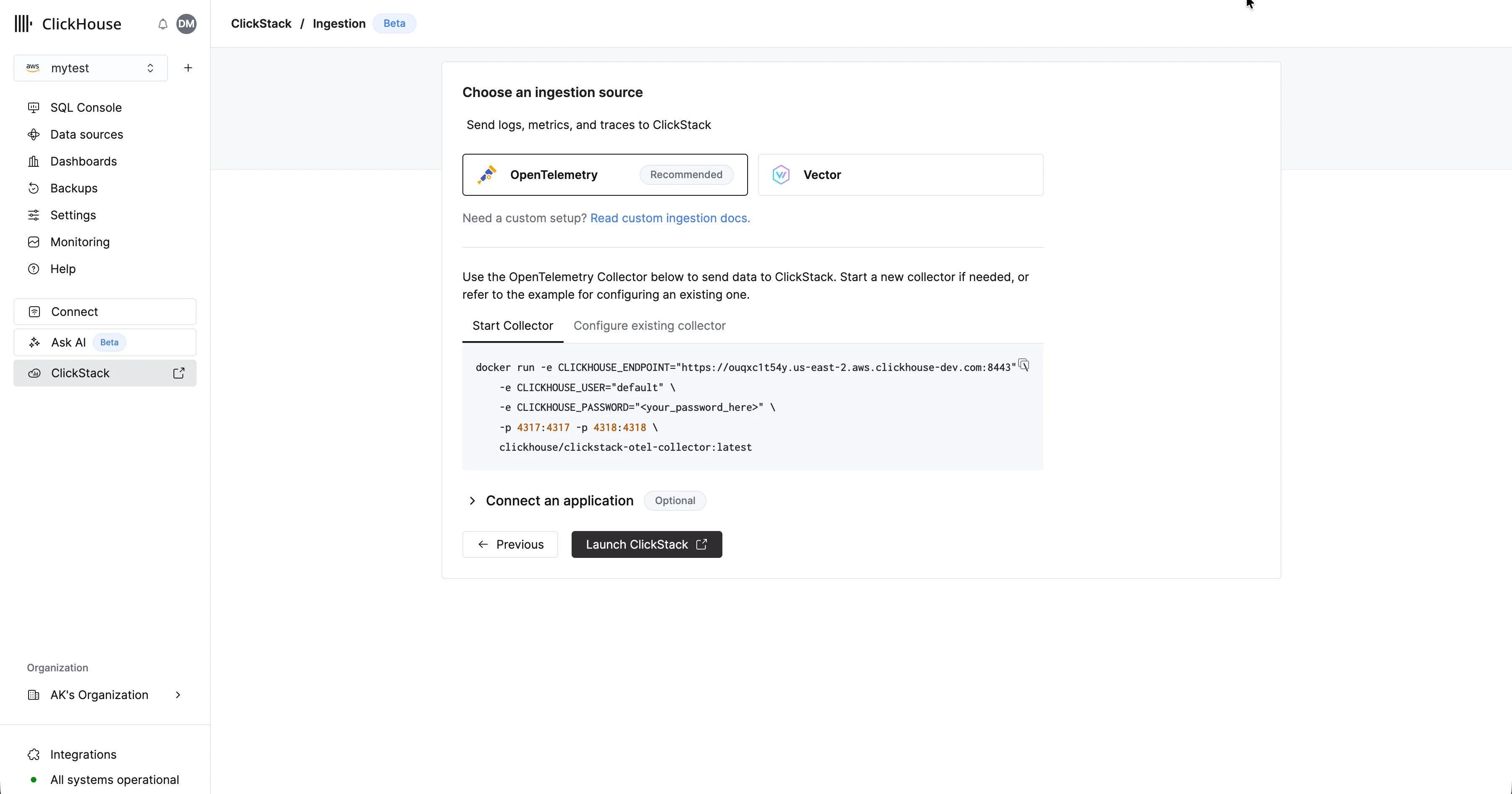
OpenTelemetry recomendadoRecomendamos fortemente o uso do OpenTelemetry como formato de ingestão.
Ele oferece a experiência mais simples e otimizada, com schemas prontos para uso projetados especificamente para funcionar com eficiência no ClickStack.
Para enviar dados do OpenTelemetry para o Managed ClickStack, recomenda-se usar um OpenTelemetry Collector. O collector atua como um gateway que recebe dados do OpenTelemetry das suas aplicações (e de outros collectors) e os encaminha para o ClickHouse Cloud.Se você ainda não tiver um em execução, inicie um collector usando as etapas abaixo. Se você já tiver collectors em execução, também disponibilizamos um exemplo de configuração.Inicie um collector
O conteúdo a seguir presume o caminho recomendado: usar a distribuição ClickStack do OpenTelemetry Collector, que inclui processamento adicional e é otimizada especificamente para o ClickHouse Cloud. Se você quiser usar seu próprio OpenTelemetry Collector, consulte “Configurar collectors existentes.”Para começar rapidamente, copie e execute o comando Docker mostrado.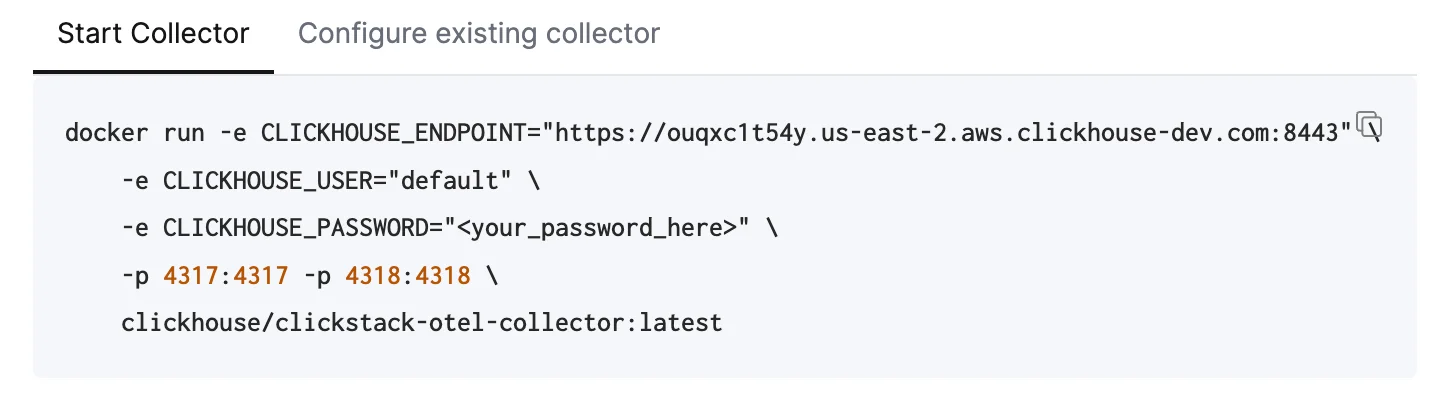 Esse comando já deve incluir suas credenciais de conexão preenchidas.
Esse comando já deve incluir suas credenciais de conexão preenchidas.Implantação em produçãoEmbora esse comando use o usuário default para se conectar ao Managed ClickStack, você deve criar um usuário dedicado ao colocar em produção e ajustar sua configuração. Configurar collectors existentes
Também é possível configurar seus próprios OpenTelemetry Collectors existentes ou usar sua própria distribuição do collector.Para isso, fornecemos um exemplo de configuração do OpenTelemetry Collector que usa o exportador ClickHouse com as definições apropriadas e expõe receivers OTLP. Essa configuração corresponde às interfaces e ao comportamento esperados pela distribuição ClickStack.Para mais detalhes sobre como configurar collectors do OpenTelemetry, consulte “Ingestão com OpenTelemetry.”Iniciar ingestão (opcional)
Se você tiver aplicações ou infraestrutura existentes para instrumentar com OpenTelemetry, acesse os guias relevantes vinculados na UI.Para instrumentar suas aplicações e coletar traces e logs, use os SDKs compatíveis para a sua linguagem, que enviam dados ao seu OpenTelemetry Collector, atuando como gateway para ingestão no Managed ClickStack.Os logs podem ser coletados usando OpenTelemetry Collectors executados no modo agent, encaminhando dados para o mesmo collector. Para monitoramento de Kubernetes, siga o guia dedicado. Para outras integrações, consulte nossos guias de início rápido.Dados de demonstração
Como alternativa, se você não tiver dados existentes, experimente um dos nossos conjuntos de dados de exemplo. Vector é um pipeline de dados de observabilidade de alto desempenho e independente de fornecedor, especialmente popular para ingestão de logs devido à sua flexibilidade e ao baixo consumo de recursos.Ao usar o Vector com o ClickStack, os usuários são responsáveis por definir seus próprios esquemas. Esses esquemas podem seguir as convenções do OpenTelemetry, mas também podem ser totalmente personalizados, representando estruturas de eventos definidas pelo usuário.Timestamp obrigatórioO único requisito rígido do Managed ClickStack é que os dados incluam uma coluna de timestamp (ou um campo de tempo equivalente), que pode ser declarada ao configurar a fonte de dados na UI do ClickStack.
Criar um banco de dados e uma tabela
O Vector exige que uma tabela e um esquema sejam definidos antes da ingestão de dados.Primeiro, crie um banco de dados. Isso pode ser feito por meio do console do ClickHouse Cloud.Por exemplo, crie um banco de dados para logs:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
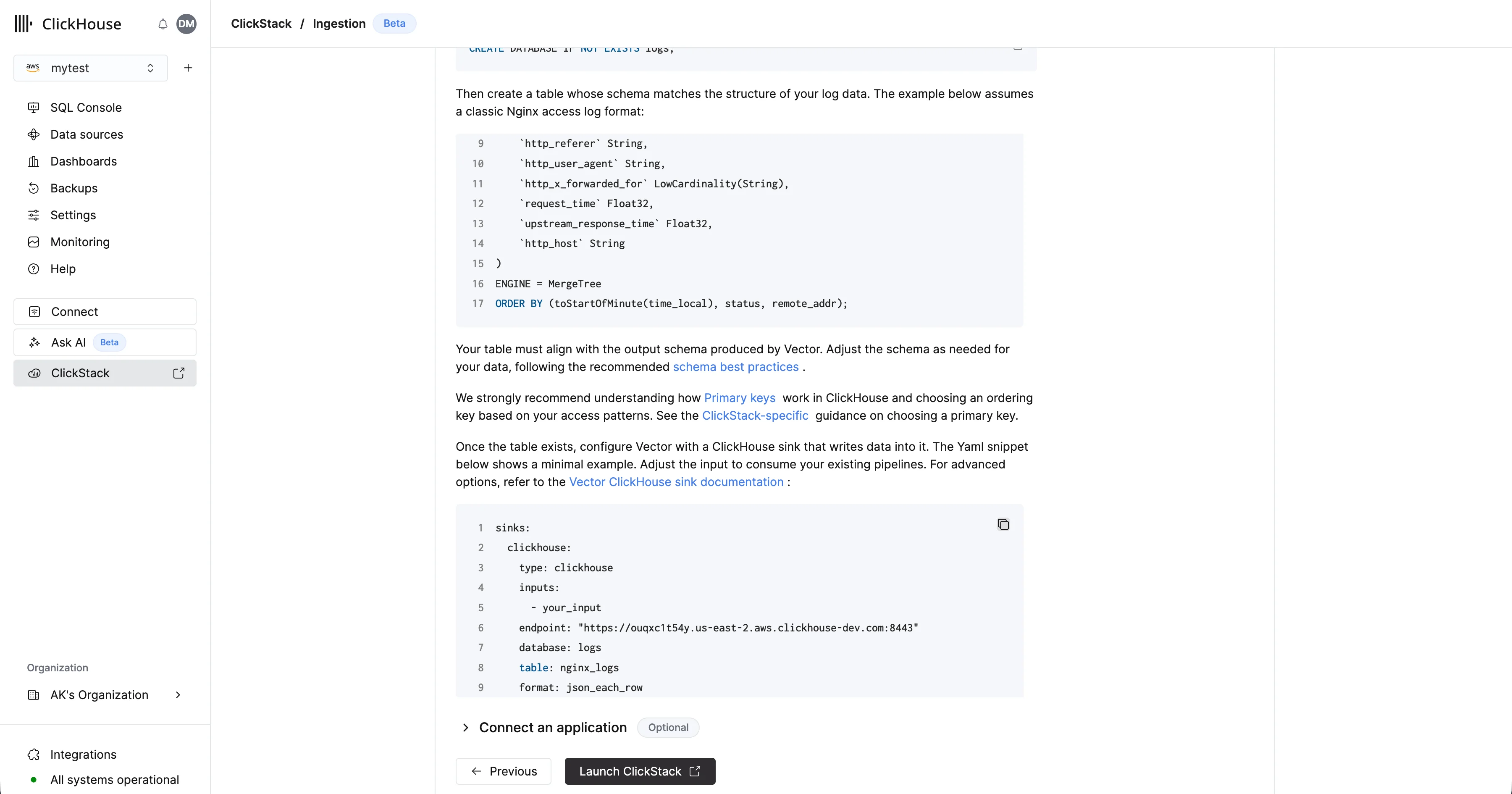 Para ver mais exemplos de ingestão de dados com o Vector, consulte “Ingestão com o Vector” ou a documentação do sink ClickHouse do Vector para opções avançadas.
Para ver mais exemplos de ingestão de dados com o Vector, consulte “Ingestão com o Vector” ou a documentação do sink ClickHouse do Vector para opções avançadas. Acesse a UI do ClickStack
Selecione ‘Launch ClickStack’ para acessar a UI do ClickStack (HyperDX). Você será autenticado automaticamente e redirecionado.As fontes de dados serão criadas automaticamente para quaisquer dados do OpenTelemetry.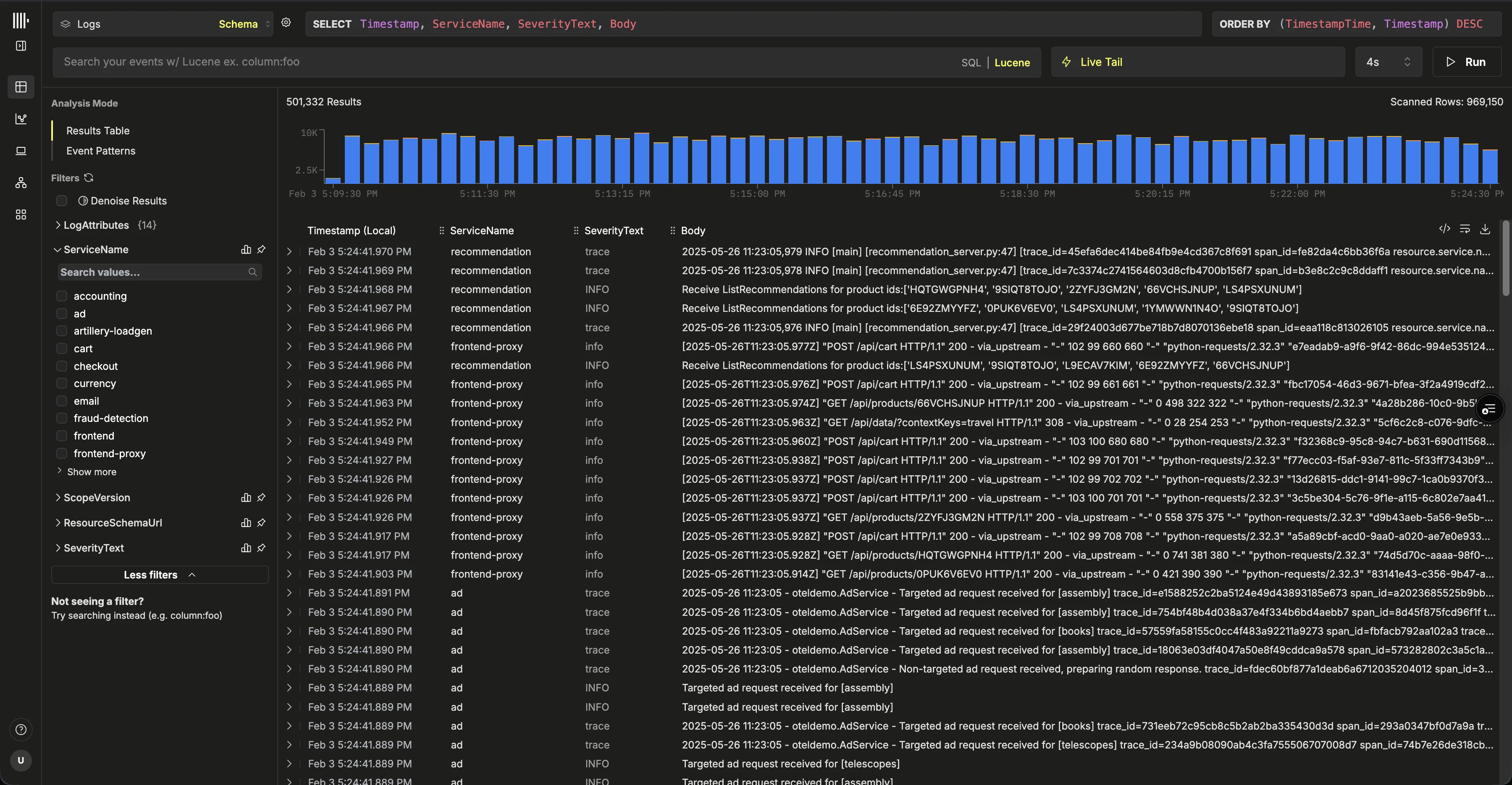
Se você estiver usando o Vector, precisará criar suas próprias fontes de dados. Na primeira vez que fizer login, será solicitado que você crie uma. Abaixo, mostramos uma configuração de exemplo para uma fonte de dados de logs.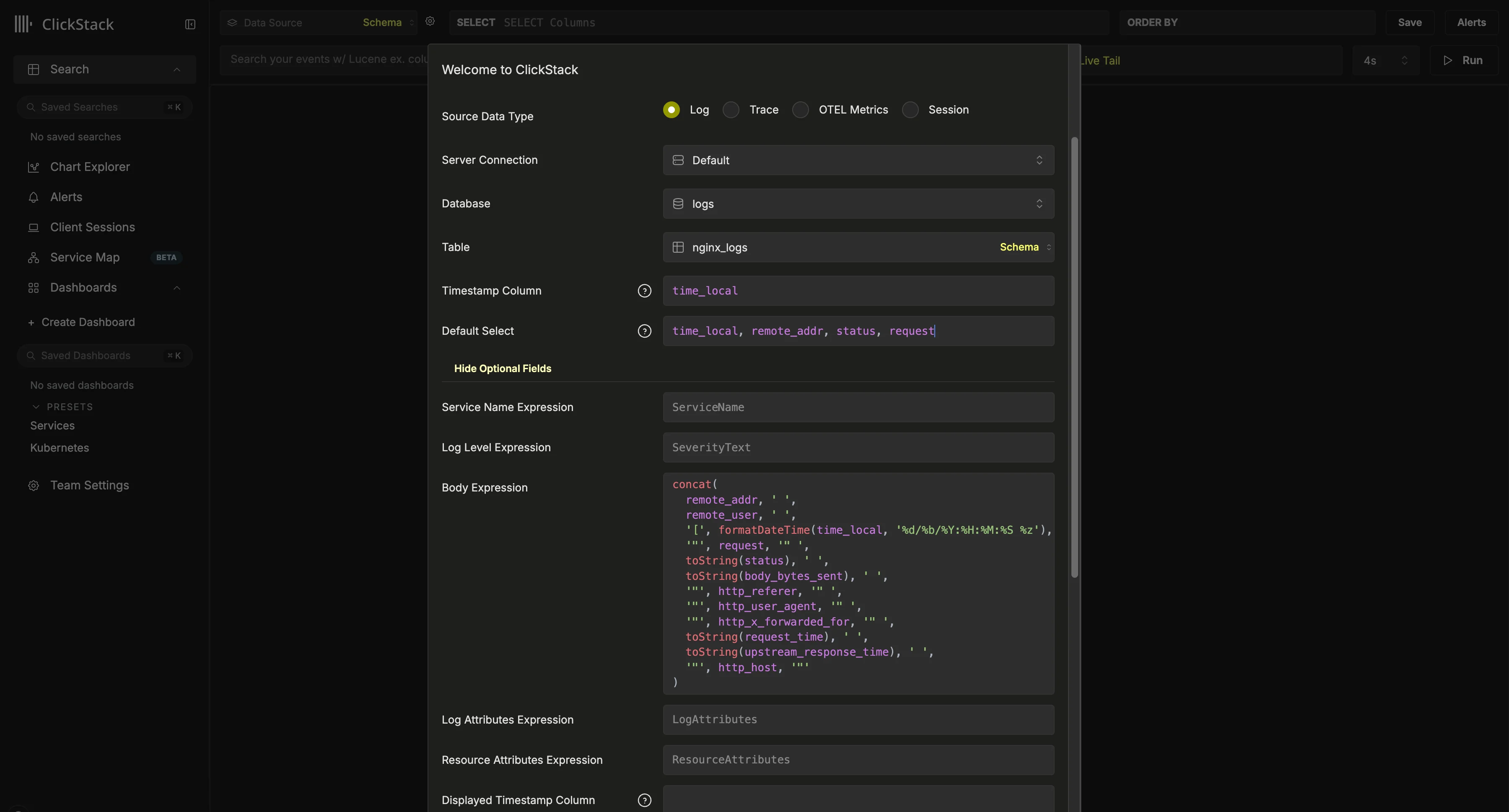 Essa configuração pressupõe um esquema no estilo Nginx, com uma coluna
Essa configuração pressupõe um esquema no estilo Nginx, com uma coluna time_local usada como timestamp. Sempre que possível, esta deve ser a coluna de timestamp declarada na chave primária. Essa coluna é obrigatória.Também recomendamos atualizar o Default SELECT para definir explicitamente quais colunas são retornadas na visualização de logs. Se houver campos adicionais disponíveis, como nome do serviço, nível de log ou uma coluna Body, eles também poderão ser configurados. A coluna exibida como timestamp também pode ser substituída caso seja diferente da coluna usada na chave primária da tabela e configurada acima.No exemplo acima, não existe uma coluna Body nos dados. Em vez disso, ela é definida usando uma expressão SQL que reconstrói uma linha de log do Nginx a partir dos campos disponíveis.Para ver outras opções, consulte a referência de configuração.Depois de criada, você deverá ser direcionado para a Search view, onde poderá começar imediatamente a explorar seus dados. Selecione um serviço
Na página inicial do ClickHouse Cloud, selecione o serviço no qual você deseja habilitar o Managed ClickStack.Estimativa de recursosEste guia pressupõe que você provisionou recursos suficientes para lidar com o volume de dados de observabilidade que pretende ingerir e consultar com o ClickStack. Para estimar os recursos necessários, consulte o guia Estimating Resources.Se o seu serviço do ClickHouse já hospeda cargas de trabalho existentes, como análises de aplicações em tempo real, recomendamos criar um serviço filho usando o recurso de warehouses do ClickHouse Cloud para isolar a carga de trabalho de observabilidade. Isso garante que suas aplicações existentes não sejam afetadas, mantendo os conjuntos de dados acessíveis a partir de ambos os serviços. Acesse a UI do ClickStack
Selecione ‘ClickStack’ no menu de navegação à esquerda. Você será redirecionado para a UI do ClickStack e autenticado automaticamente com base nas suas permissões do ClickHouse Cloud.Se já houver tabelas do OpenTelemetry no seu serviço, elas serão detectadas automaticamente, e as fontes de dados correspondentes serão criadas.Detecção automática de fontes de dadosA detecção automática se baseia no esquema padrão de tabelas do OpenTelemetry fornecido pela distribuição ClickStack do collector do OpenTelemetry. As fontes são criadas para o banco de dados com o conjunto mais completo de tabelas. Tabelas adicionais podem ser adicionadas como fontes de dados separadas, se necessário. Configurar ingestão
Se a detecção automática falhar ou você não tiver tabelas existentes, será solicitado que configure a ingestão.Selecione “Start Ingestion” e você será solicitado a escolher uma fonte de ingestão. O Managed ClickStack oferece suporte a OpenTelemetry e Vector como principais fontes de ingestão. No entanto, os usuários também têm a liberdade de enviar dados diretamente para o ClickHouse em seu próprio schema usando qualquer uma das integrações compatíveis com o ClickHouse Cloud.OpenTelemetry recomendadoO uso do OpenTelemetry é altamente recomendado como formato de ingestão.
Ele oferece a experiência mais simples e otimizada, com esquemas prontos para uso, projetados especificamente para funcionar de forma eficiente com o ClickStack.
Para enviar dados do OpenTelemetry para o Managed ClickStack, é recomendável usar um OpenTelemetry Collector. O collector atua como um gateway que recebe dados do OpenTelemetry das suas aplicações (e de outros collectors) e os encaminha para o ClickHouse Cloud.Se você ainda não tiver um em execução, inicie um collector usando as etapas abaixo. Se você já tiver collectors, também há um exemplo de configuração.Iniciar um collector
O texto a seguir parte do uso recomendado da distribuição ClickStack do OpenTelemetry Collector, que inclui processamento adicional e é otimizada especificamente para o ClickHouse Cloud. Se você quiser usar seu próprio OpenTelemetry Collector, consulte “Configurar collectors existentes.”Para começar rapidamente, copie e execute o comando Docker mostrado.Modifique este comando com as credenciais do seu serviço, anotadas quando você criou o serviço.Implantação em produçãoEmbora este comando use o usuário default para se conectar ao Managed ClickStack, você deve criar um usuário dedicado ao colocar em produção e ajustar sua configuração. Configurar collectors existentes
Também é possível configurar seus OpenTelemetry Collectors existentes ou usar sua própria distribuição do collector.Para isso, é fornecido um exemplo de configuração do OpenTelemetry Collector que usa o exportador ClickHouse com as configurações adequadas e expõe receivers OTLP. Essa configuração corresponde às interfaces e ao comportamento esperados pela distribuição ClickStack.Um exemplo dessa configuração é mostrado abaixo (as variáveis de ambiente serão preenchidas automaticamente se forem copiadas da UI):receivers:
otlp/hyperdx:
protocols:
grpc:
include_metadata: true
endpoint: "0.0.0.0:4317"
http:
cors:
allowed_origins: ["*"]
allowed_headers: ["*"]
include_metadata: true
endpoint: "0.0.0.0:4318"
processors:
batch:
memory_limiter:
# 80% da memória máxima até 2G, ajuste para ambientes com pouca memória
limit_mib: 1500
# 25% do limite até 2G, ajuste para ambientes com pouca memória
spike_limit_mib: 512
check_interval: 5s
connectors:
routing/logs:
default_pipelines: [logs/out-default]
error_mode: ignore
table:
- context: log
statement: route() where IsMatch(attributes["rr-web.event"], ".*")
pipelines: [logs/out-rrweb]
exporters:
debug:
verbosity: detailed
sampling_initial: 5
sampling_thereafter: 200
clickhouse/rrweb:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
logs_table_name: hyperdx_sessions
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
clickhouse:
database: default
endpoint: <clickhouse_cloud_endpoint>
password: <your_password_here>
username: default
ttl: 720h
timeout: 5s
retry_on_failure:
enabled: true
initial_interval: 5s
max_interval: 30s
max_elapsed_time: 300s
service:
pipelines:
traces:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
metrics:
receivers: [otlp/hyperdx]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/in:
receivers: [otlp/hyperdx]
exporters: [routing/logs]
logs/out-default:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse]
logs/out-rrweb:
receivers: [routing/logs]
processors: [memory_limiter, batch]
exporters: [clickhouse/rrweb]
Iniciar a ingestão (opcional)
Se você tiver aplicações ou infraestrutura existentes para instrumentar com OpenTelemetry, acesse os guias relevantes vinculados em “Conectar uma aplicação”.Para instrumentar suas aplicações para coletar traces e logs, use os SDKs de linguagem compatíveis, que enviam dados para seu OpenTelemetry Collector, atuando como gateway para ingestão no Managed ClickStack.Os logs podem ser coletados usando OpenTelemetry Collectors em execução no modo agent, encaminhando dados para o mesmo collector. Para monitoramento de Kubernetes, siga o guia dedicado. Para outras integrações, consulte nossos guias de início rápido. Vector é um pipeline de dados de observabilidade de alto desempenho e independente de fornecedor, especialmente popular para ingestão de logs devido à sua flexibilidade e ao baixo consumo de recursos.Ao usar o Vector com o ClickStack, os usuários são responsáveis por definir seus próprios esquemas. Esses esquemas podem seguir as convenções do OpenTelemetry, mas também podem ser totalmente personalizados, representando estruturas de eventos definidas pelo usuário.Timestamp obrigatórioO único requisito estrito do Managed ClickStack é que os dados incluam uma coluna de timestamp (ou um campo de tempo equivalente), que pode ser declarada ao configurar a fonte de dados na UI do ClickStack.
Crie um banco de dados e uma tabela
O Vector exige que uma tabela e um esquema sejam definidos antes da ingestão de dados.Primeiro, crie um banco de dados. Isso pode ser feito por meio do console do ClickHouse Cloud.Por exemplo, crie um banco de dados para logs:CREATE DATABASE IF NOT EXISTS logs
CREATE TABLE logs.nginx_logs
(
`time_local` DateTime,
`remote_addr` IPv4,
`remote_user` LowCardinality(String),
`request` String,
`status` UInt16,
`body_bytes_sent` UInt64,
`http_referer` String,
`http_user_agent` String,
`http_x_forwarded_for` LowCardinality(String),
`request_time` Float32,
`upstream_response_time` Float32,
`http_host` String
)
ENGINE = MergeTree
ORDER BY (toStartOfMinute(time_local), status, remote_addr);
Acesse a interface do ClickStack
Depois de concluir a configuração da ingestão e começar a enviar dados, selecione “Next”.Se você tiver feito a ingestão de dados do OpenTelemetry usando este guia, as fontes de dados serão criadas automaticamente e nenhuma configuração adicional será necessária. Você pode começar a explorar o ClickStack imediatamente. Você será direcionado para a Search view, com uma fonte selecionada automaticamente, para que possa começar a executar consultas na hora.É isso — está tudo pronto 🎉.
Se você tiver feito a ingestão de dados via Vector ou outra fonte, será solicitado que configure a fonte de dados.A configuração acima pressupõe um schema no estilo Nginx, com uma coluna time_local usada como timestamp. Sempre que possível, essa deve ser a coluna de timestamp declarada na chave primária. Essa coluna é obrigatória.Também recomendamos atualizar o Default SELECT para definir explicitamente quais colunas são retornadas na visualização de logs. Se houver campos adicionais disponíveis, como nome do serviço, nível de log ou uma coluna body, eles também poderão ser configurados. A coluna exibida como timestamp também pode ser substituída se for diferente da coluna usada na chave primária da tabela e configurada acima.No exemplo acima, não existe uma coluna Body nos dados. Em vez disso, ela é definida usando uma expressão SQL que reconstrói uma linha de log do Nginx a partir dos campos disponíveis.Para outras opções possíveis, consulte a referência de configuração.Depois que a fonte estiver configurada, clique em “Save” e comece a explorar seus dados.
- Navegue até seu serviço no console do ClickHouse Cloud
- Vá para Configurações → Acesso ao SQL Console
- Defina o nível de permissão apropriado para cada usuário:
- Service Admin → Full Access - Necessário para habilitar alertas
- Service Read Only → Read Only - Pode visualizar dados de observabilidade e criar dashboards
- No access - Não pode acessar o HyperDX
Alertas exigem acesso de administradorPara habilitar alertas, pelo menos um usuário com permissões de Service Admin (mapeadas para Full Access no menu suspenso de Acesso ao SQL Console) precisa fazer login no HyperDX pelo menos uma vez. Isso provisiona um usuário dedicado no banco de dados para executar as consultas de alerta.
Como o ClickStack seleciona a capacidade computacional
- Se você abrir o ClickStack a partir de um serviço somente leitura, todas as consultas emitidas pela UI do ClickStack serão executadas nessa capacidade computacional somente leitura.
- Se você abrir o ClickStack a partir de um serviço de leitura e gravação, o ClickStack usará essa capacidade computacional.
Nenhuma configuração adicional no ClickStack é necessária para garantir o comportamento somente leitura.
Para executar o ClickStack em capacidade computacional somente leitura:
- Crie ou identifique um serviço do ClickHouse Cloud no warehouse configurado como somente leitura.
- No console do ClickHouse Cloud, selecione o serviço somente leitura.
- Inicie o ClickStack no menu de navegação à esquerda.
Depois de iniciado, a UI do ClickStack será vinculada automaticamente a esse serviço somente leitura.
Adicionando mais fontes de dados
Usando esquemas do OpenTelemetry
Table com o valor otel_logs para criar uma fonte de logs. Todas as outras configurações devem ser detectadas automaticamente, permitindo que você clique em Salvar Nova Fonte de Dados.
Para criar fontes para traces e métricas do OTel, você pode selecionar Criar Nova Fonte de Dados no menu superior.
A partir daí, selecione o tipo de fonte necessário e, em seguida, a tabela apropriada. Por exemplo, para traces, selecione a tabela otel_traces. Todas as configurações devem ser detectadas automaticamente.
Correlacionando fontesObserve que diferentes fontes de dados no ClickStack — como logs e traces — podem ser correlacionadas entre si. Para habilitar isso, é necessária uma configuração adicional em cada fonte. Por exemplo, na fonte de logs, você pode especificar uma fonte de traces correspondente e vice-versa na fonte de traces. Consulte “Fontes correlacionadas” para mais detalhes. Usando esquemas personalizados
Escolha de esquema: Map vs JSON
Map(LowCardinality(String), String) por padrão. Esse é o esquema recomendado para cargas de trabalho de observabilidade. Em combinação com a serialização de map em buckets e índices de texto nas chaves e nos valores do map, ele permite lookups seletivos sem a sobrecarga de ingestão por chave das subcolunas JSON dinâmicas.
Um esquema do tipo JSON está disponível em beta para avaliação em cargas de trabalho com um conjunto pequeno e estável de chaves de atributo. Ele não é recomendado como padrão. Consulte Map vs tipo JSON para ver a comparação completa e as variáveis de ambiente necessárias para habilitar o suporte a JSON.