- Escalado automático del cómputo, independiente del almacenamiento
- Retención de bajo costo y prácticamente ilimitada basada en almacenamiento de objetos
- Posibilidad de aislar de forma independiente las cargas de trabajo de lectura y escritura con warehouses
- Autenticación integrada
- Backups automatizados
- Funciones de seguridad y cumplimiento normativo
- Actualizaciones sin interrupciones
Regístrate en ClickHouse Cloud
Para crear un servicio de Managed ClickStack en ClickHouse Cloud, primero completa el primer paso de la guía de inicio rápido de ClickHouse Cloud.Scale vs EnterpriseRecomendamos este nivel Scale para la mayoría de las cargas de trabajo de ClickStack. Elija el nivel Enterprise si necesita funciones de seguridad avanzadas, como SAML, CMEK o cumplimiento de HIPAA. También ofrece perfiles de hardware personalizados para implementaciones de ClickStack de gran tamaño. En estos casos, le recomendamos ponerse en contacto con el soporte.
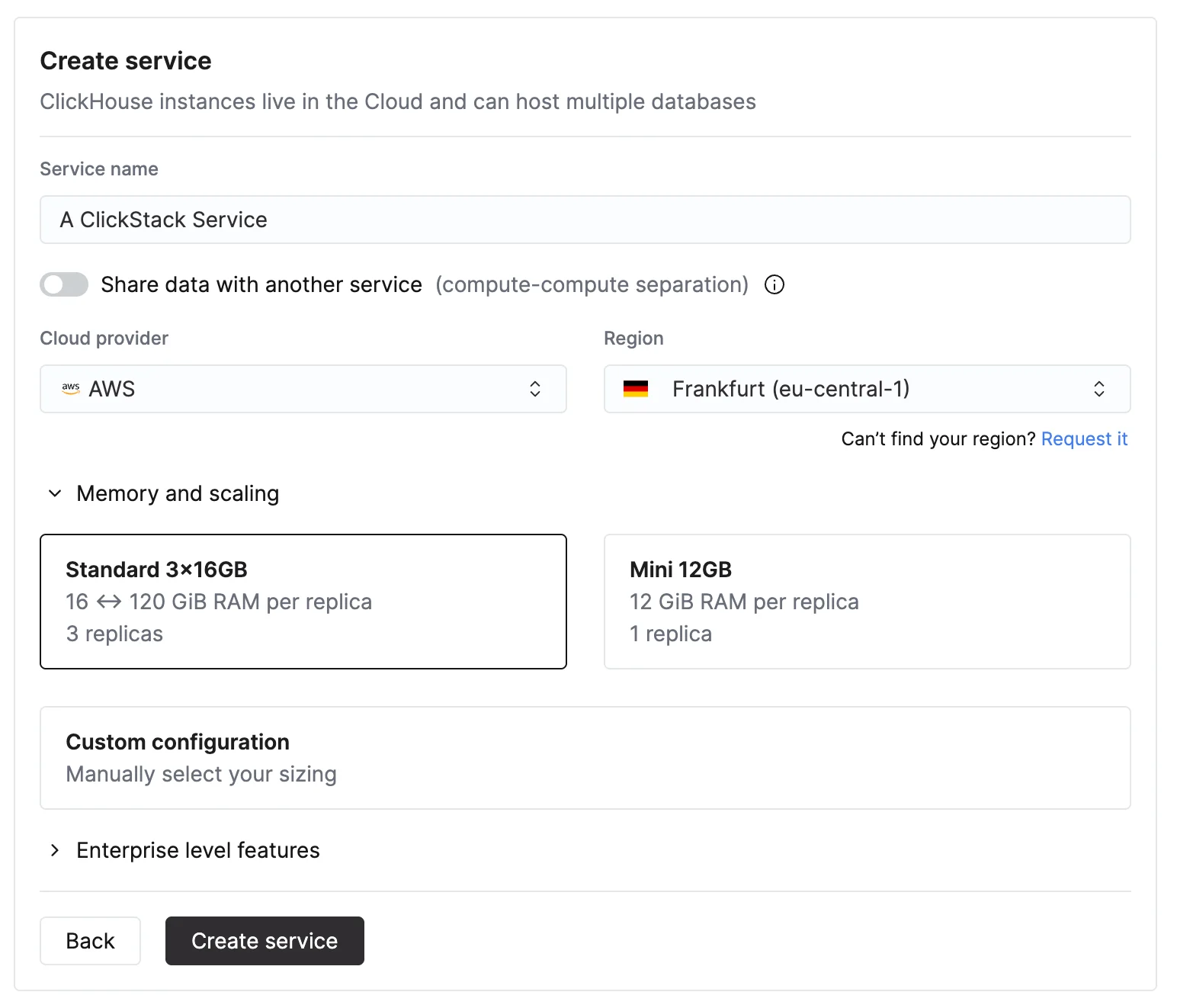
| Volumen mensual de ingestión | Capacidad de cómputo recomendada |
|---|---|
| < 10 TB / mes | 2 vCPU × 3 réplicas |
| 10–50 TB / mes | 4 vCPU × 3 réplicas |
| 50–100 TB / mes | 8 vCPU × 3 réplicas |
| 100–500 TB / mes | 30 vCPU × 3 réplicas |
| 1 PB+ / mes | 59 vCPU × 3 réplicas |
- El volumen de datos se refiere al volumen mensual de ingestión sin comprimir y se aplica tanto a logs como a traces.
- Los patrones de consulta son típicos de los casos de uso de observabilidad, y la mayoría de las consultas se centran en datos recientes, por lo general de las últimas 24 horas.
- La ingestión es relativamente uniforme a lo largo del mes. Si espera tráfico irregular o picos, debe aprovisionar capacidad adicional.
- El almacenamiento se gestiona por separado mediante object storage de ClickHouse Cloud y no es un factor limitante para la retención. Suponemos que a los datos retenidos durante periodos más largos se accede con poca frecuencia.
Estos valores son solo estimaciones y deben utilizarse como referencia inicial. Los requisitos reales dependen de la complejidad de las consultas, la concurrencia, las políticas de retención y la variación del throughput de ingestión. Supervise siempre el uso de recursos y escale según sea necesario.
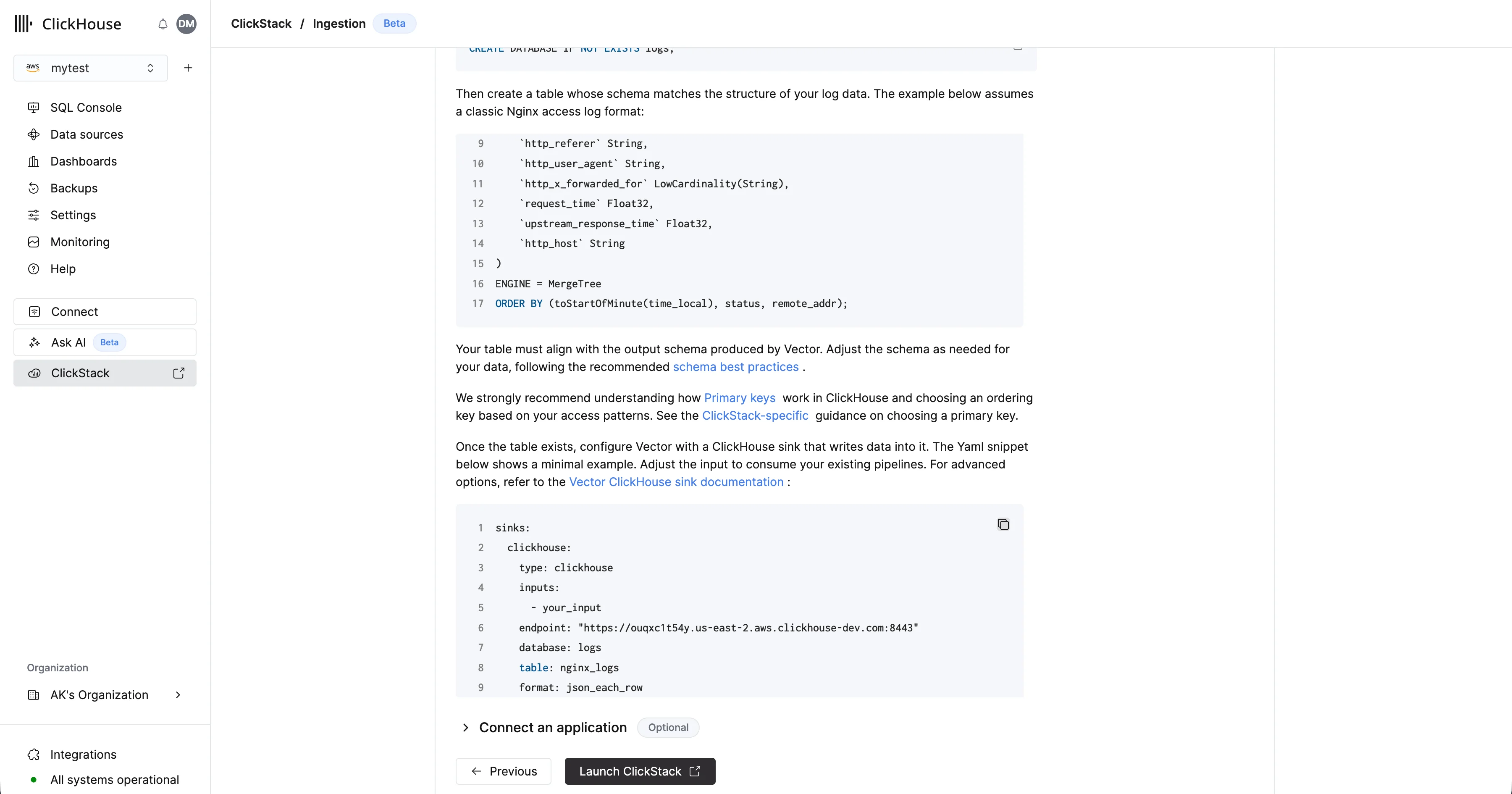
Configura la ingestión
Una vez aprovisionado el servicio, asegúrate de que esté seleccionado y haz clic en “ClickStack” en el menú de la izquierda.
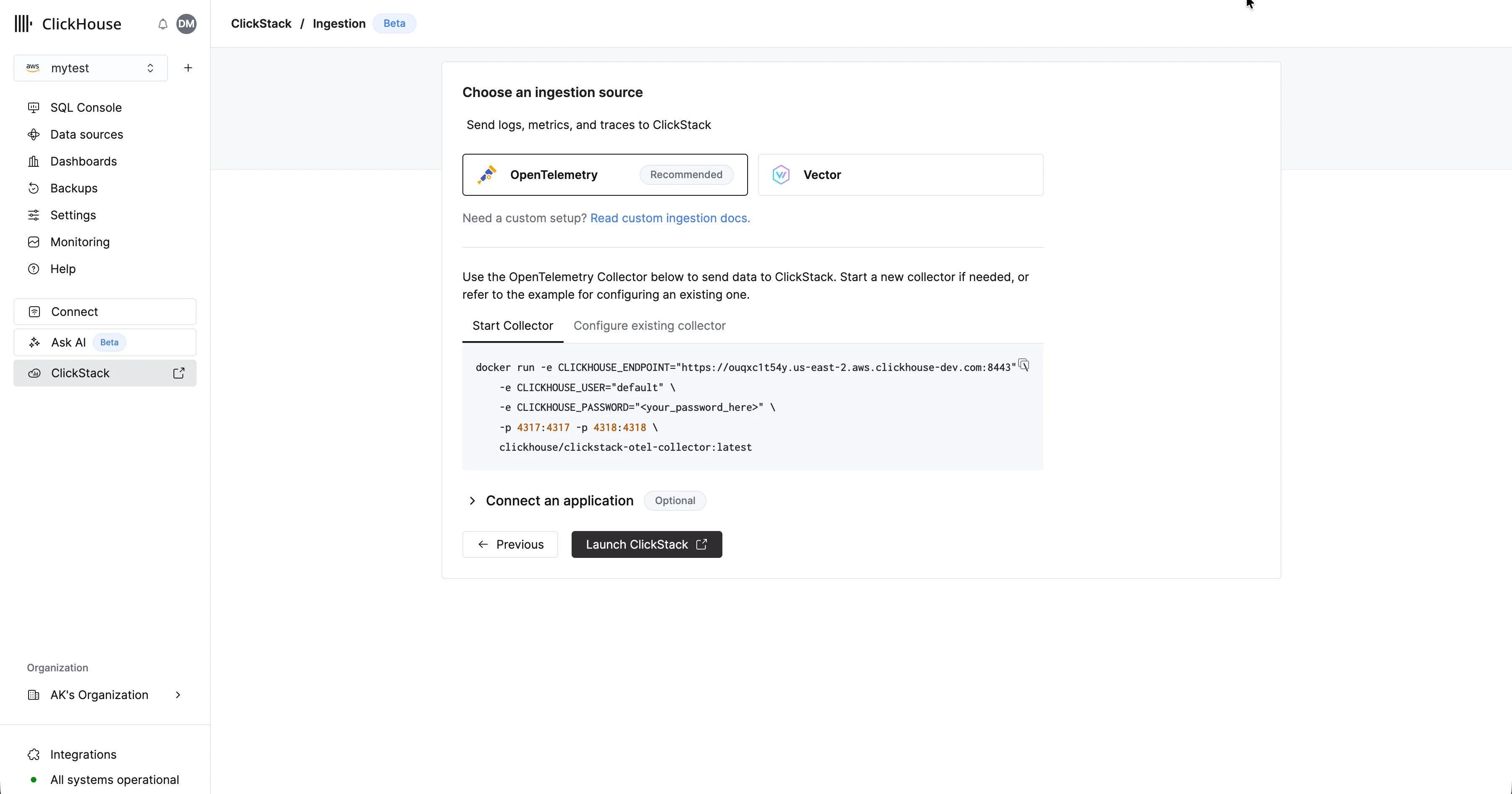
OpenTelemetry recomendadoSe recomienda encarecidamente usar OpenTelemetry como formato de ingestión.
Ofrece la experiencia más sencilla y optimizada, con esquemas listos para usar diseñados específicamente para funcionar de forma eficiente con ClickStack.
- OpenTelemetry
- Vector
Para enviar datos de OpenTelemetry a Managed ClickStack, se recomienda usar un OpenTelemetry Collector. El collector actúa como un gateway que recibe datos de OpenTelemetry de sus aplicaciones (y de otros collectors) y los reenvía a ClickHouse Cloud.Si aún no tiene uno en ejecución, inicie un collector siguiendo los pasos a continuación. Si ya tiene collectors existentes, también se incluye un ejemplo de configuración.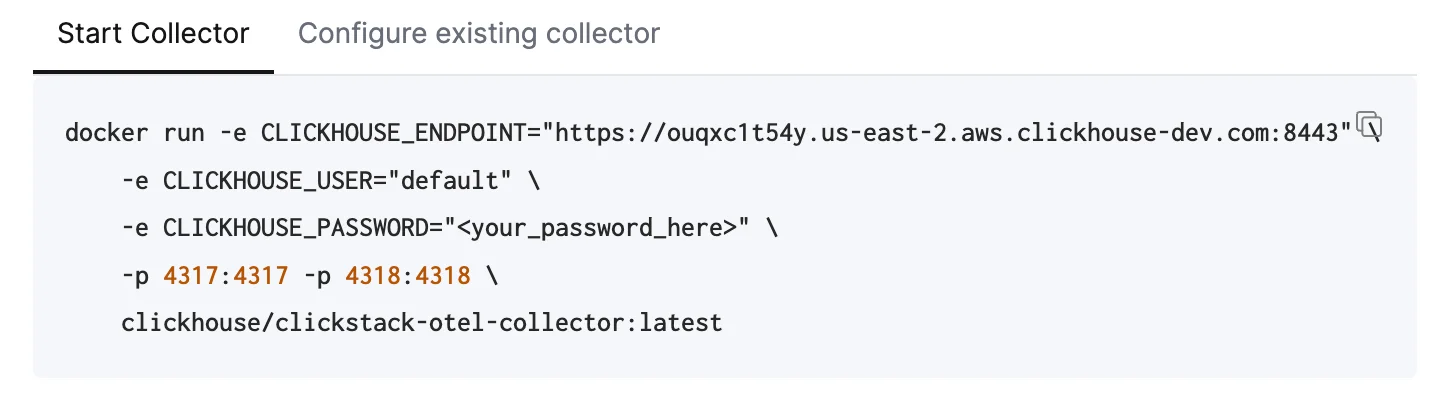
Iniciar un collector
A continuación se asume la ruta recomendada: usar la distribución de ClickStack de OpenTelemetry Collector, que incluye procesamiento adicional y está optimizada específicamente para ClickHouse Cloud. Si desea usar su propio OpenTelemetry Collector, consulte “Configurar collectors existentes.”Para empezar rápidamente, copie y ejecute el comando de Docker que se muestra.Despliegue en producciónAunque este comando usa el usuario
default para conectarse a Managed ClickStack, debería crear un usuario dedicado al pasar a producción y modificar su configuración.Configurar collectors existentes
También es posible configurar sus propios OpenTelemetry Collectors existentes o usar su propia distribución del collector.Se requiere el exportador de ClickHouseSi está usando su propia distribución, por ejemplo la imagen contrib, asegúrese de que incluya el exportador de ClickHouse.
Iniciar la ingestión (opcional)
Si tiene aplicaciones o infraestructura existentes para instrumentar con OpenTelemetry, vaya a las guías pertinentes enlazadas desde la UI.Para instrumentar sus aplicaciones y recopilar traces y logs, use los SDKs de lenguajes compatibles, que envían datos a su OpenTelemetry Collector, que actúa como gateway para la ingestión en Managed ClickStack.Los logs pueden recopilarse usando OpenTelemetry Collectors que se ejecutan en modo agent y reenvían datos al mismo collector. Para la monitorización de Kubernetes, siga la guía específica. Para otras integraciones, consulte nuestras guías de inicio rápido.Datos de demostración
Como alternativa, si no tiene datos existentes, pruebe uno de nuestros datasets de ejemplo.- Dataset de ejemplo - Cargue un dataset de ejemplo de nuestra demo pública. Diagnostique un problema sencillo.
- Archivos locales y métricas - Cargue archivos locales y supervise el sistema en OSX o Linux usando un OTel collector local.
Ve a la interfaz de ClickStack
Seleccione ‘Launch ClickStack’ para acceder a la interfaz de ClickStack (HyperDX). Se le autenticará automáticamente y se le redirigirá.- OpenTelemetry
- Vector
Se crearán automáticamente orígenes de datos para todos los datos de OpenTelemetry.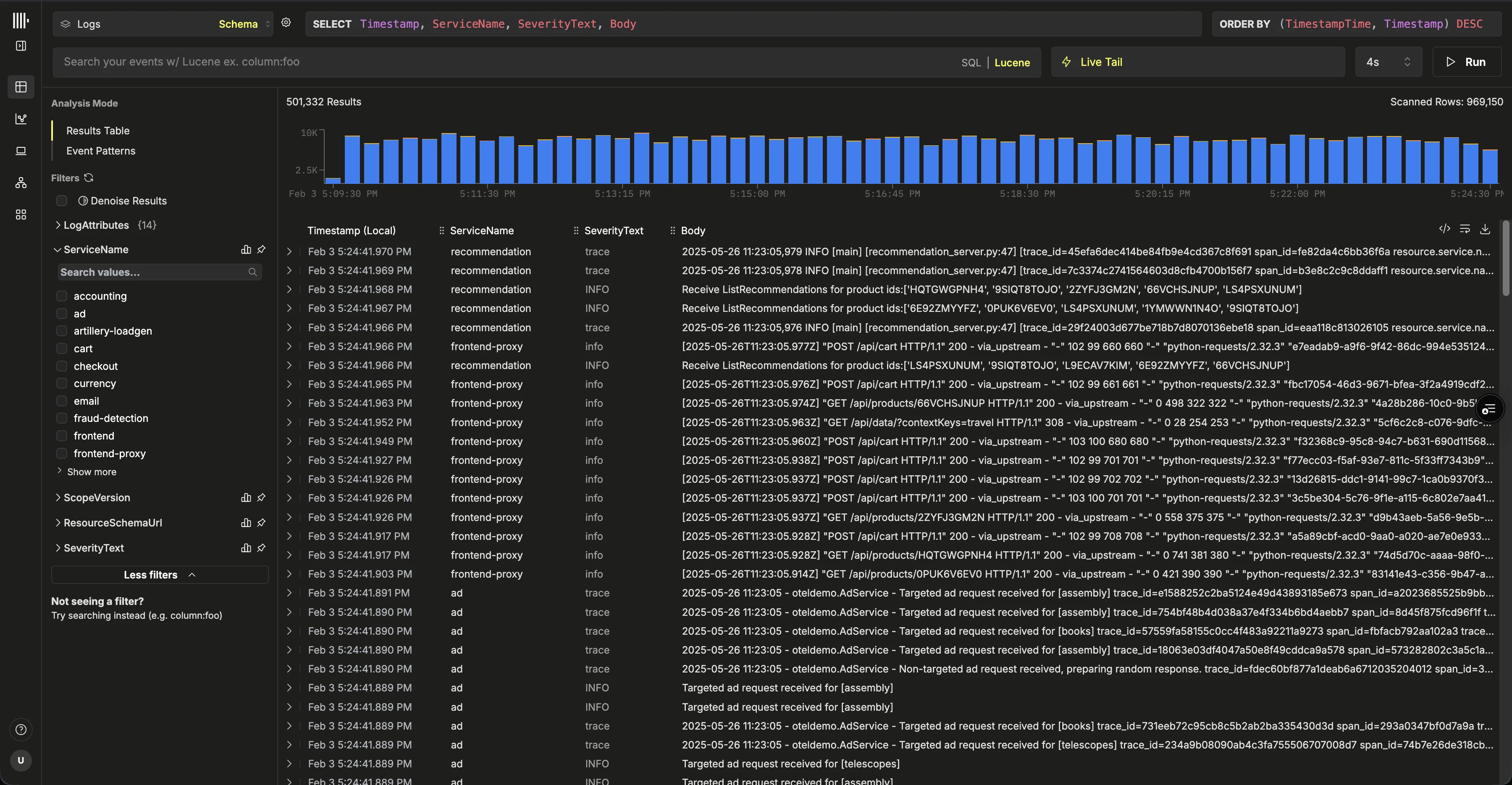
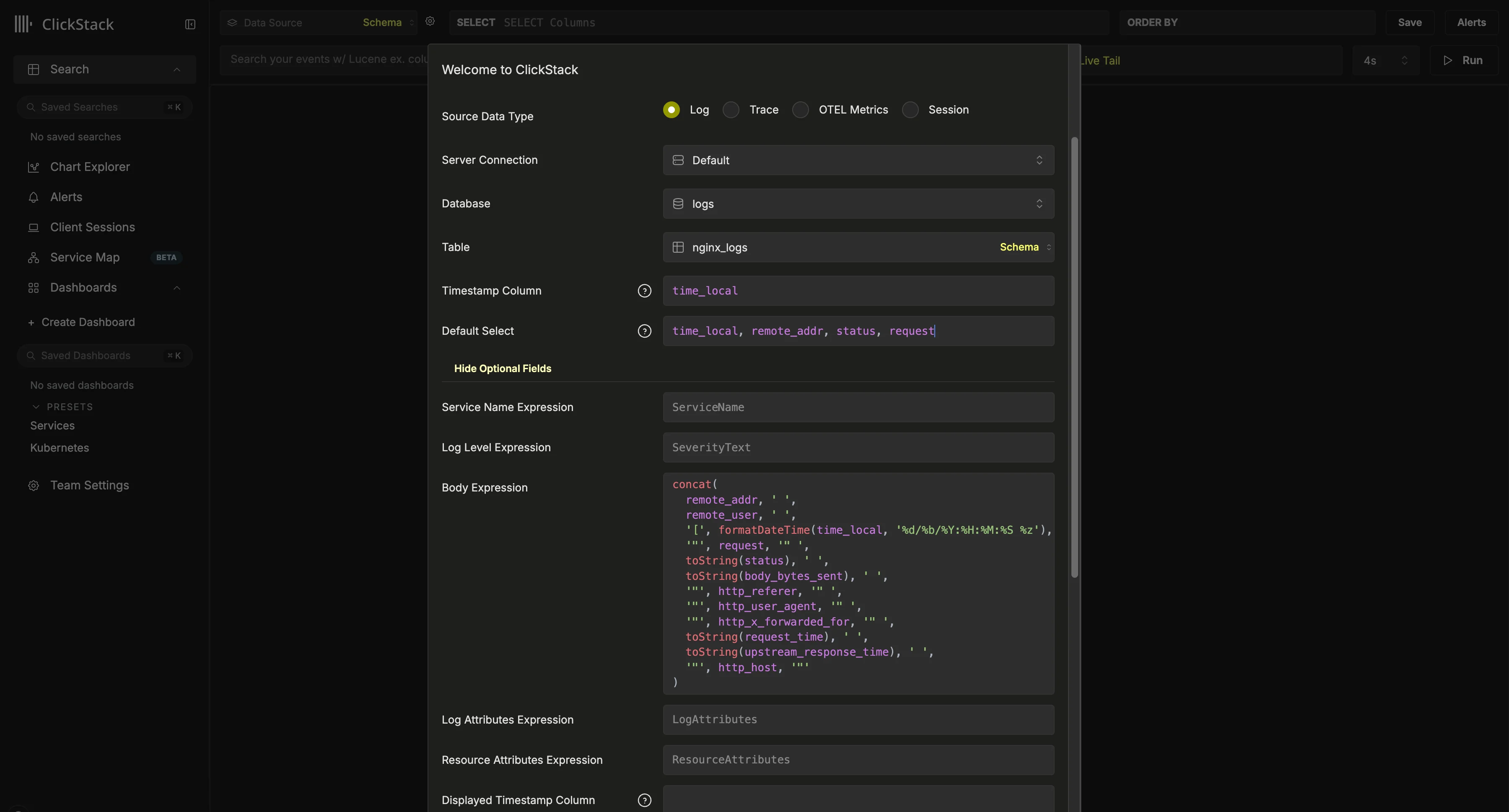
Y eso es todo: ya está listo. 🎉Siga explorando ClickStack: empiece a buscar logs y trazas, vea cómo se correlacionan logs, trazas y métricas en tiempo real, cree dashboards, explore mapas de servicios, descubra event deltas y patterns, y configure alertas para adelantarse a los problemas.